Very inspired by your diagram @Cornelius_Hunter! Here is my version…
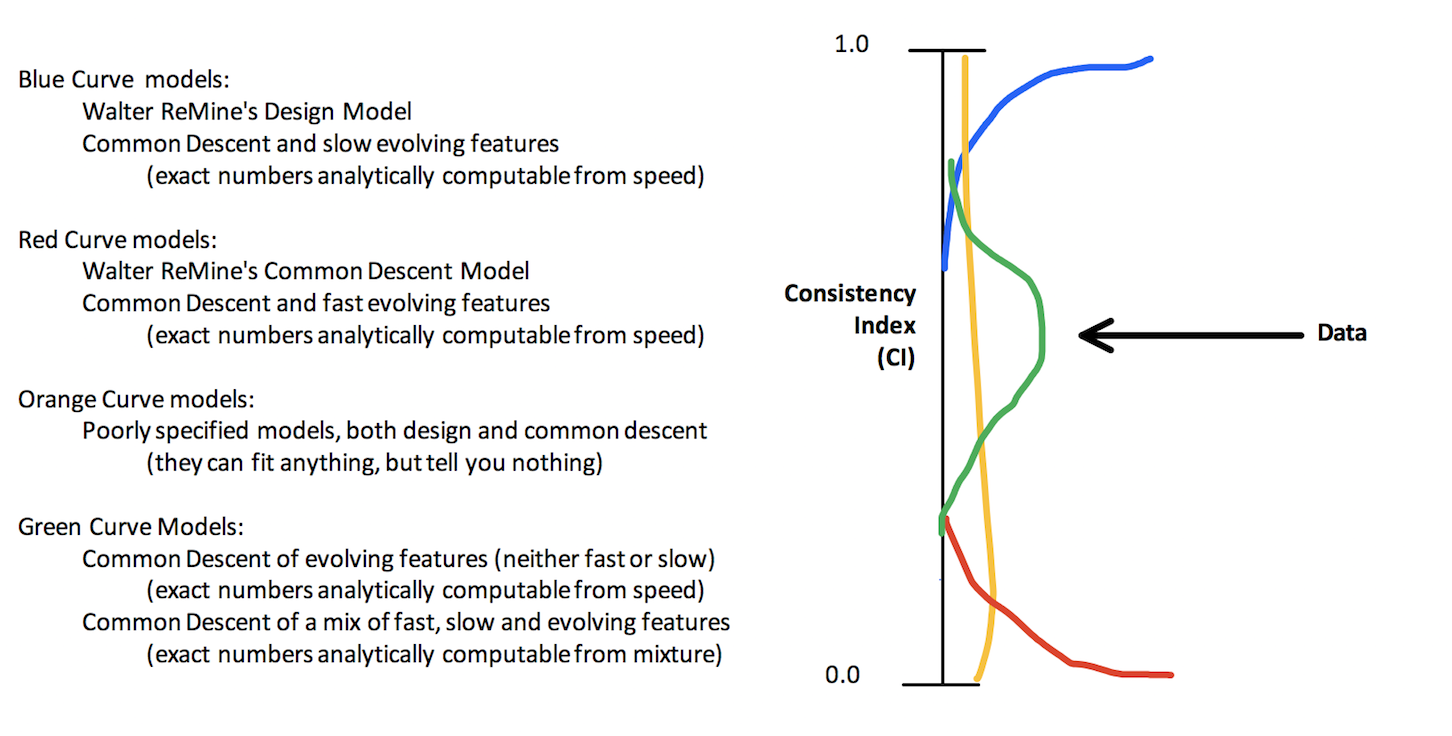
A key variable you are missing is the “speed” at which a features evolves (which is often directly measurable). Depending on this parameter, common descent will make different predictions. This isn’t cheating, because we can directly measure the speed in many cases (especially with DNA), and this gives us a way of analytically computing the expectation.
Any how, I think (in my opinion), ReMine’s model corresponds to the blue line, the features used in this analysis correspond to a mixture of slow and fast evolving features, so in this case CD corresponds to the green line. And your model corresponds to the orange line, because it is not specified at all.
So the data ends up fitting CD the best. I should point out that I believe in design too; design by common descent. So in no way does this rule out that God created us. Rather, it tells us that common descent is the best design principle to understand biology.