I think it depends what you are looking at. In the sections we can accurately compare, you could look at the ERVs:
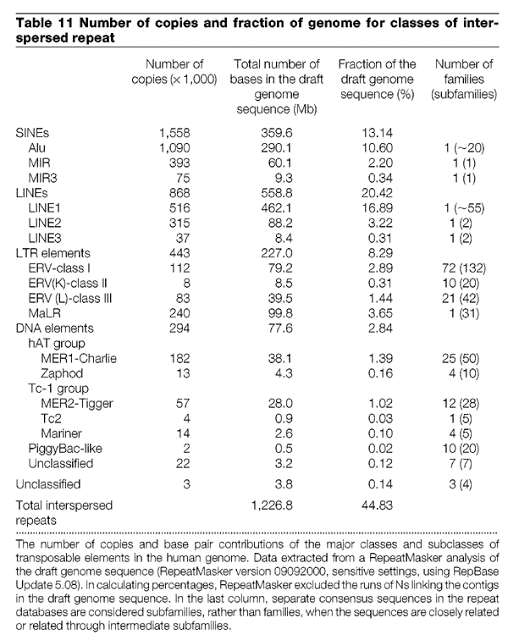
There are 203,000 of them (see column 1, listed in thousands), and yet here is the table outlining the differences between human and chimps:

Less than 400 of those 203,000 are different. The recent ERV thread discusses this in more detail: Why Aren't the Twin Locations of >100k+ ERV's (human vs. chimp) Discussed More?
Outside of such comparisons, there is obviously no way to accurately quantify what percent difference one should expect… other than the human and chimp genomes are much more similar than they have to be for the same function!
Here is one particular gene (see Evolution Basics - BioLogos):

As the article notes: there are over 53 million different codon combinations to produce the exact same amino acid sequence. There is no reason that any supernatural creation should/would include such similarities the Creator actually used common descent/evolution to make such species as you can get identical amino acids as per this chart: