We’ll add you to Foxe’s Book of Martyrs.
2 Likes
The important thing to note here is how different the alignment success was going in the two directions: 90% of the human genome aligned to chimpanzee, while 96% of the chimpanzee genome aligned to human. Now this could mean that humans have an extra 6% of their genome that is unique to our species, but it is far more likely that the lower success represents the imperfect nature of the chimpanzee assembly that the human is being aligned against. This is the obvious conclusion, and presumably the source of the 96% in the paper’s abstract.
Now, of course it’s possible that if the equivalent 6% of the chimpanzee genome were better assembled, it would show little similarity with human DNA and that alignment in both directions would only be about 90% successful. But I see no reason to think that that would be the case.
It’s appropriate to have doubts. If you want to draw conclusions about the overall identity of human and chimpanzee DNA, you should have some kind of understanding of how good your procedure is at estimating that quantity, especially since the procedure in question wasn’t designed for this purpose and since nobody here knows much about it. Most of the DNA you’re interested in – in particular the segmental duplications – lie in the trickiest parts of the genome to align, and the tricky bits can be quite tricky. Recent segmental duplications are nearly identical in sequence, and yes, I’d like to know how often the alignment pipeline picks the wrong copy, thereby breaking the best reciprocal alignment.
1 Like
Seems fair. Flayed alive, burned at the stake, had to reply to an old thread.
4 Likes
Too much for what? To confirm common descent or refute evolution?
Yes Bill. Is the amount of difference incompatible with the current evolutionary model? If, say, a maximum of 6% is compatible with a common ancestor 6 million years ago and the measured difference is 12% then that would refute that hypothesis. It could however be consistent with a common ancestor 12 million years ago. But can anyone tell us what the limit is?
From the discussion above it is pretty clear that 98% similarity is not valid. Just saying it was calculated using a different method does not make it correct if the method was flawed. I believe that figure was calculated ~50 years ago using DNA re-crystallization which was the best available at the time but has now been shown to give inaccurate results.
@aarceng You are assuming the difference would apply linearly with time and I don’t know how anyone could know that to be true. DNA doesn’t last for 6 million years.
The paper indicates that 90% of the human genome is 98% identical to the chimp genome. I am no biologist but that appears to show we are closely related and certainly it is no stretch to say we have a common ancestor.
The 98% comes from a published paper and I see no reason to question it’s validity. Did you read the paper? Richard’s number comes from scripts that he wrote and haven’t been published. That isn’t a reason to question it’s validity though. I have asked him for some comparisons between chimp and gorilla or human and gorilla to get a feel for what the number is supposed to show and so far have heard nothing but the crickets chirping.
The paper indicates that the human reference genome, version GRCh38 was used and it appears to be recent.
1 Like
I think it depends what you are looking at. In the sections we can accurately compare, you could look at the ERVs:
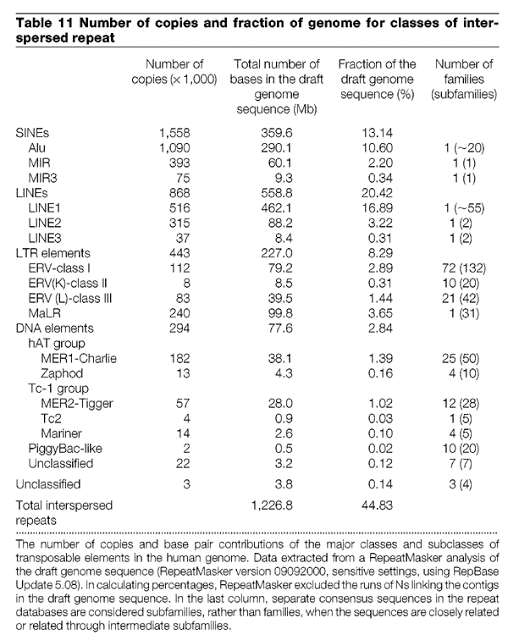
There are 203,000 of them (see column 1, listed in thousands), and yet here is the table outlining the differences between human and chimps:

Less than 400 of those 203,000 are different. The recent ERV thread discusses this in more detail: Why Aren't the Twin Locations of >100k+ ERV's (human vs. chimp) Discussed More?
Outside of such comparisons, there is obviously no way to accurately quantify what percent difference one should expect… other than the human and chimp genomes are much more similar than they have to be for the same function!
Here is one particular gene (see Evolution Basics - BioLogos):

As the article notes: there are over 53 million different codon combinations to produce the exact same amino acid sequence. There is no reason that any supernatural creation should/would include such similarities the Creator actually used common descent/evolution to make such species as you can get identical amino acids as per this chart:
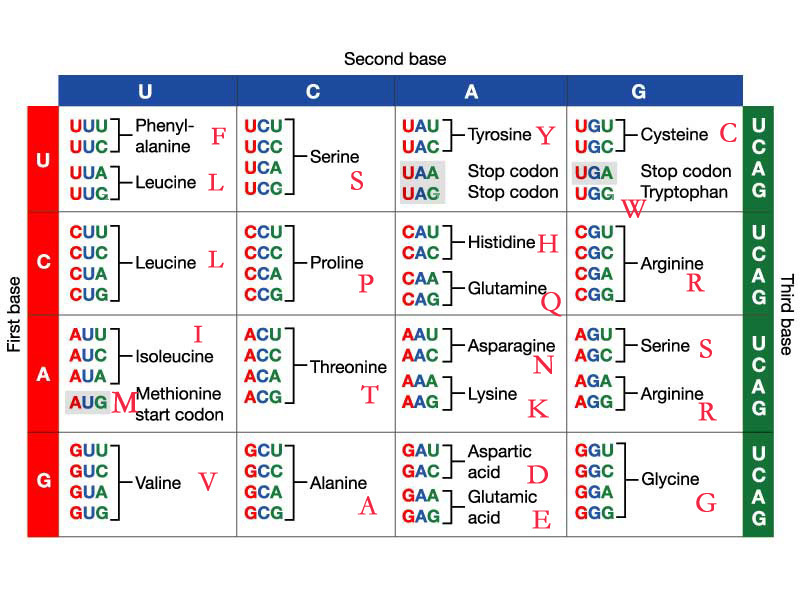
3 Likes
Short answer: only one of the numbers that’s been tossed around poses any real challenge to the standard evolutionary model, and t’s not one anyone has paid any attention to. It’s also quite likely wrong.
To compare the expected amount of genetic difference between humans and chimpanzees with what we see, we have to know several things: the (selectively neutral) mutation rate per generation, the average length of a generation in both lineages, the time when the two lineages diverged, and the effective size of the ancestral population before the split (a larger population means more genetic diversity in the population, and more differences that get randomly shuffled into the two lineages). We have some estimates for all of these quantities, and most of them are quite fuzzy, so there’s lots of uncertainty in the expected value.
One key value is the mutation rate. Now, there are different kinds of mutation involved here, with different mutation rates. We can break them down into three basic classes: single-base substitutions (one base mutates into another), small insertions and deletions (‘indels’), and large insertions and deletions (‘structural variation’).
Substitutions are the easiest to assess (just look for individual different bases in otherwise identical sequence), the most common, and probably the ones that contribute the least to the total difference. It also happens to be the only class of mutation for which we have a reasonably good estimate of the mutation rate without assuming common descent. In the chimp genome paper, the rate of single-base differences between humans and chimps was estimated to be 1.23%. Given current estimates of the mutation rate, this is consistent with common ancestry, although it’s on the high end of what might be expected, and implies a fairly old separation (say, 7 million years ago rather than 6) and a large ancestral population size.
Small indels were estimated in the chimp genome paper to represent ~1.5% of unique human sequence, more than single-base differences even though there are fewer individual differences (since a single indel can involve many bases). I don’t know of a good estimate for the rate of new indels, but the observed number of differences is in the right ballpark, based on the number we see when comparing two humans.
Structural variation is the hardest to assess, and the category for which we have the least knowledge about mutation rates. It may well represent the largest contribution to the overall difference (anywhere from “more than 0” to 5% strikes me as plausible), but it tells us just about nothing about common descent, since we really don’t know how much to expect. This is why I don’t find estimating the overall divergence something of interest.
The one estimated divergence that would cause trouble for common descent is the estimate of the single-base divergence from the paper @RichardBuggs quoted, and which I responded to yesterday. Their value was 1.93%, rather than 1.23%. While the absolute difference between the two estimates is small, the later one is 50% greater than the original one. 1.23% requires old divergence and large ancestral population, and 1.93% would be difficult to accommodate with plausible values. However, the higher value is also likely wrong. The paper in question notes that their program is optimized for speed, not sensitivity and is less sensitive than another program, LASTZ, that is commonly used. When @RichardBuggs came up with his own estimate of the single-base divergence, based on public data and LASTZ, he got values of 1.12% and 1.24%, depending on how he did the comparison. Since the underlying data in this recent paper was basically the same data Richard used, it’s fair to conclude that the software in the paper is responsible for the difference. It’s a good illustration, though, of how dangerous it is to draw sweeping conclusions based on imperfect estimates of divergence.
5 Likes
Hi @glipsnort welcome back. I think perhaps “circling” is a more appropriate adjective for this thread than “stale”! Thanks for your new contributions, which are as valuable as ever. I was hoping you might in particular have a chance to respond to this post (especially part b) when you have time:
many thanks,
Richard
I’m afraid most of the discussion here is over my head. So I went to google to find some summary statements regarding our relative relatedness to chimps and the other great apes and found this at the Smithsonian Institute’s Human Origins Program here.
Apparently we and our chimp cousins differ from our next closest relative the gorilla to the same degree, 1.6%. Meanwhile both chimps and bonobos differ from ourselves by 1.2%, and all of our african kin differ from the orangutan by 3.1%. Within humans the range of variability between individuals is placed at 0.5%. So, whatever the technical basis for the comparison may be, applying the same criteria across the great apes shakes out this way.
From the perspective of this powerful test of biological kinship, humans are not only related to the great apes – we are one. The DNA evidence leaves us with one of the greatest surprises in biology: the wall between human, on the one hand, and ape or animal, on the other, has been breached. The human evolutionary tree is embedded within the great apes.
The strong similarities between humans and the African great apes led Charles Darwin in 1871 to predict that Africa was the likely place where the human lineage branched off from other animals – that is, the place where the common ancestor of chimpanzees, humans, and gorillas once lived. The DNA evidence shows an amazing confirmation of this daring prediction. The African great apes, including humans, have a closer kinship bond with one another than the African apes have with orangutans or other primates. Hardly ever has a scientific prediction so bold, so ‘out there’ for its time, been upheld as the one made in 1871 – that human evolution began in Africa.
The DNA evidence informs this conclusion, and the fossils do, too. Even though Europe and Asia were scoured for early human fossils long before Africa was even thought of, ongoing fossil discoveries confirm that the first 4 million years or so of human evolutionary history took place exclusively on the African continent. It is there that the search continues for fossils at or near the branching point of the chimpanzee and human lineages from our last common ancestor.
I agree with their concluding statement there that it is proper to think of ourselves as a third “chimp”. Doesn’t change the fact that we have a suite of upgrades which make us very unusual in the animal world. Biologically it is clear where we fit in the family tree. Goes to show that humble origins do not rule out great accomplishments.
5 Likes
Thank you for your patience. On May 12th I responded to @T_aquaticus on a very similar point. Based on alignments available at UCSC:
I don’t have stats to hand for gorilla, but I hope this gives you the kind of context you want. I’m afraid I don’t have time to do further species comparisons at the moment.
My focus throughout this thread has simply been to come up with an accurate current assessment of how similar the human and chimpanzee genomes are. I am making no claims about “what the number is supposed to show”. I did make some brief comments on this point in my original articles in 2007 (see the start of this thread), but my purpose in the current discussion is simply to respond to @DennisVenema who enquired about my current view on how similar the human and chimpanzee genomes are.
I am still waiting for @DennisVenema to substantiate his claim in Adam and the Genome that “our entire genomes are either around 95 per cent or 98 per cent identical depending on how one counts the effects of deletions of small blocks of DNA” (p. 32).
But if the exact percentages are only slightly different is there not the risk of winning a battle but losing the war? The point appears to be that we are closely related. Thanks
1 Like
Is this what is referred to as an academic question?
Hi Richard,
Well, I’m still waiting for you to propose a hypothesis for a sudden bottleneck to two hominins at ~700 KYA followed by explosive growth that is not miraculous, but as the song goes, you can’t always get what you want.
But I think you’re being a bit pedantic here. Your critique only really works if you press the word “entire” to mean “absolutely every nucleotide”. Maybe “genome-wide” would have been a better choice, but “entire” works just fine as well. And yes - 95% is the best estimate we have for the genome-wide identity of chimps and humans if you count indels on a per-nucleotide basis. That’s the published value based on the largest sample we have, and you’ve still given us no reason to suppose that the bits left over that haven’t been chased down to the nth degree are going to be significantly different than that value. Even if they are, it will most likely be due to indels of highly repetitive DNA, which is really hard to account for in any case.
But back to “entire”. If you google “entire” for dictionary definitions, you’ll see things like this:
The whole of, without missing any part. E.g. “I’ve traveled the entire world.” Not so! says the pedant. You may have travelled to every country, but have you visited every city? Every town? Every street in every town? Every house on every street? Every room in every house? Every square foot of every room?
Clearly this gets a bit silly.
Or take this recent headline:
“Pompeo: Iran will face ‘wrath of entire world’ if it pursues nuclear weapons.”
Not so! says the pedant. North Korea will probably approve, for that matter lots of Iranians will as well. There’s a guy in Albania who’s in favour as well. Clearly claiming the entire world will be wrathful is off base.
You also omitted my summary statement from your quote from Adam and the Genome:
“No matter how you slice it, the human and chimpanzee genomes are nearly identical to each other.”
That is what you have to deal with, even if you decide you want to slice it a little differently. That and all the other evidence for common ancestry. If you want to oppose common ancestry of humans and chimpanzees, it’s going to take a lot more than quibbling over the precise percent identity between the genomes.
9 Likes
Not really, in the sense that it’s not a question an academic scientist is likely to ask. “What is the rate of single-base substitutions between the two genomes?” is an academic question, as is “What fraction of the human genome represents unique sequence not present in the chimpanzee genome?” In contrast, “What is the overall identify between the two genomes?” is ambiguous and doesn’t correspond to any obvious scientific question.
Suppose there has been a recent duplication of a million base pair segment in humans, with both copies now ~2.5% different from a single chimpanzee region, and 0.2% different from each other. Is that a million bp of unique sequence in the human genome? What scientific question are you trying to answer with this comparison?
2 Likes
As I mentioned up there ^^ long ago, the singular focus of trying to maximize the differences between humans and chimpanzees and minimize the “% identity value” has only ever been a tactic to attempt to reduce confidence in common ancestry.
It’s for this reason that I find the lack of engagement on the other myriad genomic evidences for common ancestry disingenuous on this point. If it’s really common ancestry we’re discussing, then let’s discuss the whole breadth of the evidence.
It’s been a lot harder to be an antievolutionist since we started sequencing genomes.
4 Likes
Okay. . .
I hesitate to conclude that it is now 5%. The MUMmer4 paper concluded that 4% of the chimpanzee genome did not align against the human, which looks quite consistent with the sum of 2.7% from segmental duplications and 1.5% from smaller indels (from the original chimp paper). Aligning the human against chimpanzee of course gives a smaller aligned fraction, but that’s inevitable when aligning the more complete against the less complete genome. (Now, the reciprocal LASTZ alignments may give a different value, but that kind of dependence on method would make any conclusions quite tenuous.)
True.
Give their stated doubt that they could assemble structural arrangements correctly, I think they are eliminating a class of alignment that includes incorrect assembly as well as portions of the genome that they don’t think they can assemble correctly. That is not exactly what I said previously.
1 Like
95% seems like a defensible value based on the MUMmer4 paper, which claims 98% identity across 96% of the genome. As I argued above, I think the 98% is probably an underestimate and should be 98.8%, which gives 95% as an overall value.
2 Likes
One of the things in Adam and the Genome that I try to underscore is that the precise numbers are probably going to shift around as new technologies are brought to bear on these questions. It’s for this reason that I say things like “about 95%” and so on. I did the same for the ancestral effective population numbers (Ne). But changes in the precise numbers are not likely to invalidate the general consensus - we evolved, and we did so as a population.
No one is more interested in the “% genome identity” thing than folks trying to cast doubt on common ancestry. It’s just not a precise value that scientists are interested in, because it doesn’t answer interesting scientific questions in the way other values do (as you’ve pointed out).
6 Likes
That last sentence is everything anyone needs to know about this conversation.
7 Likes
LOL!