Steve:
Well my point was straightforward. I made the observation that the CI values often are actually closer to the random model than to 1.0 (the ideal common descent model), and that this better fits the design model than the common descent model. As I explained, design trends emerge simply due to the constraints of natural laws, the same planet, biosphere, etc. Or as Fernald put it:
Although the variety of eyes in the animal kingdom seems astonishing, physical laws have constrained solutions for collecting and focusing light to just eight types of eye optics.
You said that the consistency index data “on the face of it, it offers strong evidence for common descent.” Actually, if anything, on the face of it the data are evidence for design.
Of course, we all understand common descent can explain the evidence. But that is because common descent can explain practically any evidence. If CI ~= 1.0, common descent could explain that. Common descent can explain a wide range of outcomes, but that is not a virtue when it comes to theory evaluation.
How could you see this as strong evidence for common descent? What this points out is how far data can be from the model and (i) not only do no harm, but (ii) actually be greeted as “strong” evidence. This is not a virtue.
For instance, let’s consider this in Bayesian terms, in order to see what evolutionists are claiming here. In order for these observed CI values to be “strong” evidence, the probability of observation (low CI values) given the hypothesis of common descent, P(O|H), would need to be very high. In other words, on common descent, the CI value is very strongly expected to be down there closer to random than to 1.0. This means that for larger CI values, as it gets closer to 1.0, P(O|H) necessarily decreases significantly, and becomes pretty small.
But this clearly is not the case. On common descent, this simply does not happen. High CI values would do no harm, and in fact would be closer to the ideal common descent model. Evolutionists would of course have no problem with such findings, and certainly would interpret it more positively. P(O|H) would increase, not decrease.
The fact is, this is not good evidence for common descent, and is a better fit for design, as I have explained. So here is a notional illustration of this. For a given #taxa, you have a “random” CI band, and the observed CI values above that, and then way up higher the ideal common descent model. Evolutionists have for years complained “why would God make it appear to have evolved?!” Well here is the answer: it doesn’t. Clearly the CI values, by the evolutionist’s own reckoning, are a better fit to design than to common descent.
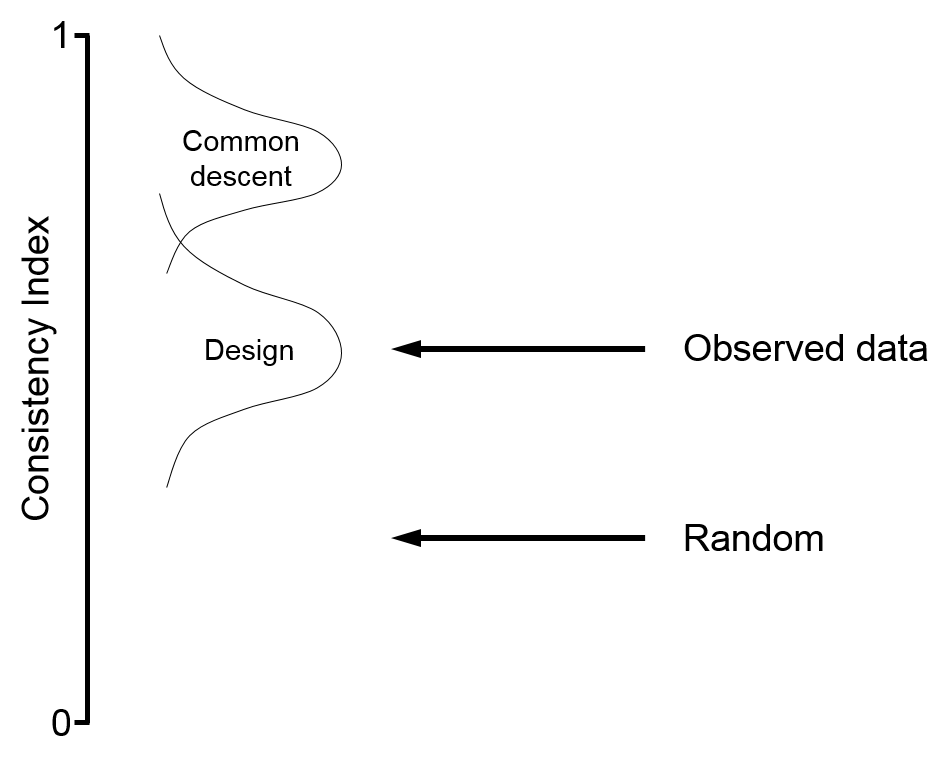
Clearly the CI values are not “strong” evidence for common descent. You can always claim that common descent is capable of explaining the evidence, but that is a very different claim. Chris lectures me on evidence interpretation, but perhaps you guys need to think a bit harder about this. Agreement is probably too much to expect, but at least to acknowledge, “OK, this is their position—this is why they say what they say, and this is the strength of their argument”, rather than straw-manning it.
When I criticize evolution, I first want to understand it in all its strength. I want to understand why evolutionists say what they say. And who knows, perhaps that exercise will change my mind. But it will do no good if I’m merely knocking down strawmen. I’m gratified when evolutionists say “I disagree with your conclusion, but I appreciate that you have represented my position in its strength.”
Instead Chris has taken the low road. He has gone the extra mile, putting words in my mouth to make it appear I am making basic, high school math mistakes and rendering my argument as absurd. I shudder to think what is said about me when I am not here to read the posts.