I have changed the alternative interpretations of consistency index data to be evolution (E) and not-evolution (E’) so as not to imply that Hunter advocates randomness rather than design. E’ could be either design or randomness or anything other than evolution, really. Also, since (without quantitative modeling) Hunter thinks evolution should predict a consistency index of 0.8, I have edited one diagram accordingly. Finally, I have added an explanation of why the consistency index is a good way to detect nested hierarchy in a common descent model. All changes are in bold.
I would like to ask a favor of everyone in this thread: could we try to maintain our focus on how to identify signal and noise, and how it affects inference from data to scientific theory? The argument over definitions is interesting–so interesting, in fact, that it perhaps deserves its own thread. ![]()
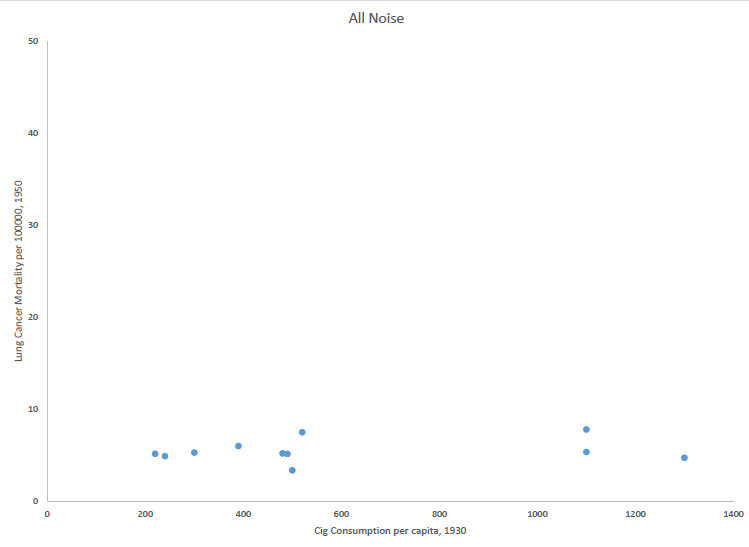
The main reason it took so long to convince the public of the causal relationship between smoking and lung cancer–other than the fact that millions of people enjoyed smoking those things–is that the data have plenty of noise. In the early 1950s Doll released the first ecological study of smoking and lung cancer. If the relationship were all signal and no noise, his data would have looked something like this:

A perfectly linear relationship.
On the other hand, if there were no relationship between smoking and lung cancer, Doll would have published a graph like this:
Random variation with no correlation.
In fact, his data contained both signal and noise:

Clearly the data show a strong positive correlation between smoking and lung cancer (diagnosed 20 years later). The p-value of this correlation lies far beyond the .05 statistical significance boundary. At the same time, there is plenty of noise: compare USA in the lower right corner with Switzerland middle left, for example.
The critics of the scientific consensus cite the noise in the data as a reason to reject the consensus. For example, Vialls cites the outliers in a different study as proof that that the consensus is wrong. But the consensus does not predict 100% signal in the data. Scientists expect noise because lung cancer has many factors: time duration of smoking, multiple environmental factors, and some (perhaps many) genetic factors. Since these factors vary independently of smoking habits, they introduce noise in the data. We also expect a significant time lag (decades) between inception of smoking and cancer diagnosis, and this lag can also differ between observations. (It would also explain why rats and mice don’t get lung cancer–have you ever met a 25 year old rat?) The key point is that the (implicitly causal) time-lagged relationship is extremely significant statistically, across many data sets besides Doll’s.
Bottom line: in the real world, there are real explanations for noise in the data on smoking and lung cancer. The noise therefore does not, by any stretch of the imagination, refute the strong, statistically significant evidence for a causal relationship between smoking and lung cancer.
Now let’s turn to our favorite scientific subject: the theory of evolution. Like the scientific consensus about smoking and lung cancer, the scientific consensus about evolution rests on a large, diverse set of data. But critics of this consensus, like @Cornelius_Hunter, do not hesitate to cite noisy data as reason to reject the theory. Let’s take a look at a notable example our friend Cornelius recently cited in another thread: Klassen’s 1991 article on the consistency index.
A consistency index measures the extent to which a set of taxa can be arranged in a hierarchical phylogeny based on measurements of some characters. Mathematically, it represents the minimum number of possible changes divided by the actual number of changes needed to represent the most parsimonious nested hierarchy. A consistency index of 1.0 means that there is a perfectly consistent hierarchical phylogeny in a set of taxa (species) based on measurements of certain characters. The theory of evolution predicts statistically significant consistency indices that indicate phylogenetic relationships. If evolution were true, Hunter claims, the CIs would be very close to 1.0–something like this:
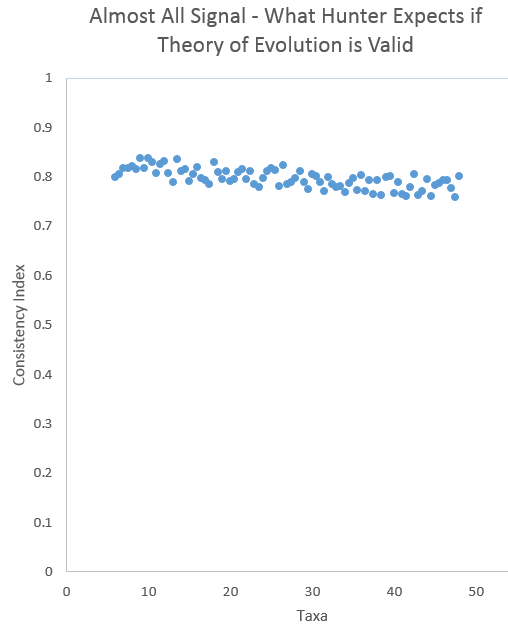
By contrast, if there were no signal of phylogenetic hierarchies, any scientist would expect 95% of the data sets to lie inside the statistical significance boundaries for a randomly constructed data set–i.e. within 2 standard deviations of the best fit curve of consistency indexes for those random data sets. Due to my inferior graphing skills, I am only providing a scatter plot without the significance boundaries:
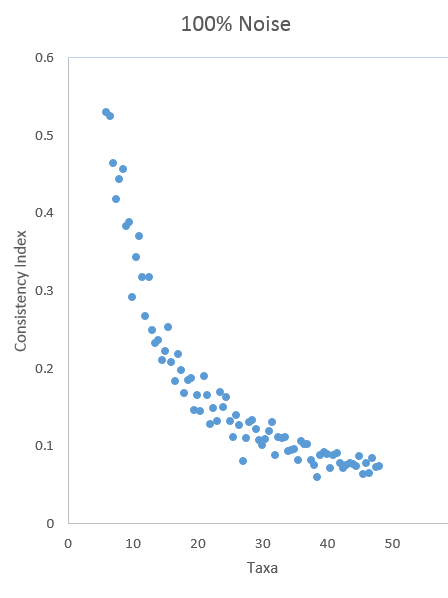
However, as with smoking and lung cancer, the actual consistency index data show both a very strong signal of hierarchical phylogeny and abundant noise:
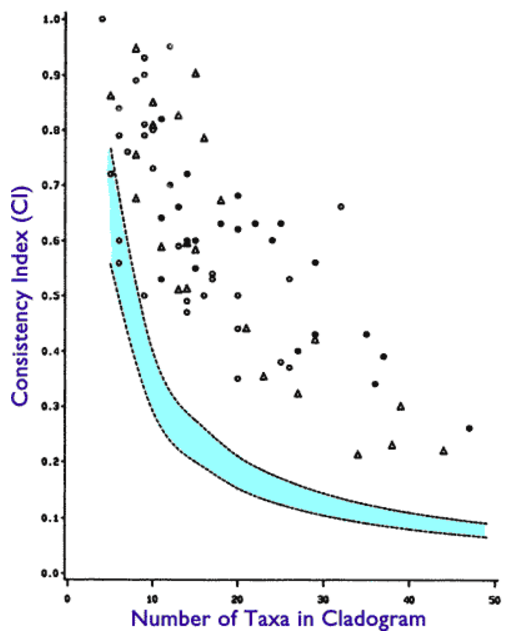
The blue region delineates where the null hypothesis is more than 5% probable.
Is it appropriate to expect significant noise in the data? Absolutely! As Matzke states:
creationists make the perfect the enemy of the good. They completely fail understand the difference between “classic homologies” – like the tetrapod limb – and the typical characters used in modern “get as many characters as you can” analyses. In the latter, organisms are atomized as finely as possible while avoiding coding the same character twice under two descriptions. Yes, it would be highly problematic to suggest that the tetrapod limb evolved twice independently. But if you take that limb, and atomize into 100+ individual characters, including the bumps and twists of each bone – is it possible that some of those bumps arose twice independently? Heck yes! If they arose once, they could arise several times, because these highly atomized characters are quite simple (unlike the whole tetrapod limb). Does this homoplasy invalidate the entire enterprise of cladistics and verifying common ancestry? Heck no! Some of those characters might have homoplasy, some might have such high homoplasy that they retain no phylogenetic signal at all (a different thing) – but if you have lots of characters, it doesn’t matter. All that is required is that, on average, most characters retain some phylogenetic signal.
Finally, it is important to address Hunter’s dramatic misunderstanding of how to determine whether a phylogenetic relationship is signaled or not. Let me put some numbers in front of you, dear reader, to explain. When there are 40 taxa, a completely random CI is 0.10, and of course the CI of a perfectly nested hierarchy would be 1.0. Hunter is claiming that if the measured CI is arithmetically closer to 0.10 than to 1.0, the hypothesis of not-evolution (call it E’) is victorious, and a hierarchical phylogeny (call it E) is disproved. I.e., according to Hunter, the value of the CI must be greater than 0.55 to signal a hierarchical phylogeny for 40 taxa. If the value is 0.54 or below, the E’ hypothesis is considered proven.
This is so wrong.
Any observation that is greater than the blue region demonstrates a hierarchical phylogeny at a statistical significance level of 95%.
The line that bisects the blue region is the mean CI for taxa with randomly assigned characters. The distance between this mean and the outer boundary of the blue region is 2.0 standard deviations (by the definition of statistical significance). Just casually observing the chart, you will notice that the vast majority of the CIs are at least 10.0 standard deviations from the mean random CI. This means that probability of the E’ hypothesis for any one of those CIs is only 0.0025.
Given that Klassen listed about 80 CIs that reached at least that level of statistical significance (and many had far greater statistical significance), the probability that the entire set of CIs can be attributed to the E’ hypothesis is 0.0025^80, or about 1 in 10^178. This is back of the envelope, of course, but it indicates just how wrong @Cornelius_Hunter’s analysis is.
Bottom line: in the real world, there are real explanations for noise in the consistency index data. The noise therefore does not, by any stretch of the imagination, refute the overwhelming, statistically significant evidence for hierarchical phylogenies among species.
But occasionally slipping up and doing the math wrong is not a sin. I hope no one who reads this thinks I am criticizing Cornelius personally. I am just criticizing the way he does math when he analyzes the consistency index data.
Sorry for the long post, but I couldn’t think of a clear way to explain this in fewer words and pictures. All the diagrams that are not attributed to specific publications were drawn in Excel 2016 by yours truly. If you got to this point, thanks for sticking with me, and I hope you learned something useful.