This is not accurate. They are estimating the average population size in a sliding window (that is quite large). They are not estimating the minimum. Just the average. The really interesting question is whether or not there is a way to determine the minimum.
Population size estimate studies, to be clear, are not testing for a brief bottleneck followed by an exponential expansion. The only paper I know that did this is the Ayala paper on MHC (http://www.pnas.org/content/91/15/6787.abstract) from 1994. Eventually we will get around to it, but this is the only published study I know that actually tests the idea. That was 25 years ago though, so the follow up studies are going to be interesting to look at.
The point that @RichardBuggs is making is that the power of population studies past about 500 kya to detect brief bottlenecks are not well studied. The fact that they do not find them, therefore, cannot be taken as evidence they do not exist. At least not yet. This is a question about detectability and statistical power.
We are not speaking theologically at all. This is about the science.
I imagine those that take this position might take it not for Genesis, but because of Paul’s statements in Acts, Romans, and I Cor. I suspect New Testament theology drives this more than Genesis hermeneutics. Whatever the case, the impact on theology should be sorted out later. Perhaps we start a thread for that?
I’m not sure I understand the question. For one, I agree that that TMRCA > 1mya are legitimate signal of ancestry, for DNA. We are not talking about segments of DNA though, but a couple with four genome copies between them both. Its an equivocation to place them at an autosomal TMRCA. Right?
Well, for one, I am an academic! =)
Also, we were brought here by the claim that “Homo sapiens” never dip below a few thousand. Though, we all know, they eventually go to zero in the past. How can we know then that they do not stop at 2 on the way to zero? Yes, this is all about definitions. No scientific study goes here, because there is not enough traction to get clarity here. Which is why heliocentric certainty is not likely.
As I understand it (and it seems was confirmed by others, there are two claims at question here.
That’s right. I’d say this higher confidence than the Y-chromosomal studies too.
That is exactly what these studies do. There is real quality work here.
If you read the papers, you will see that quite a bit of validation is going on. There is really good work being done by scientists here. It is a mistake to dismiss it this way. There is a great deal of independent validation. Often they find that specific parameters do not affect the results much (e.g. mutation rate and generation time), except to scale the time. That leaves the debate on exact dates open (and does expand the confidence intervals), but it does not invalidate the whole effort.
The question here is actually far more interesting on a scientific level. We are getting into understanding exactly what these approaches can and cannot tell us.
If this is what @DennisVenema means by his first claim, I’m not sure its defensible:
1. Homo sapiens specifically do not dip down to a single couple in 300 kya to the confidence we have in heliocentrism.
Population size estimates are always of Homo sapiens + all of our other ancestors at the time. The finding that our ancestors do not go to a single couple tells us nothing about Homo sapiens specifically, because Homo sapiens are not our only ancestors past about 50 kya.
Regarding the second claim, things are more interesting.
2. Our ancestors as a whole do not dip down to a single couple between 300 kya and 3 mya with very high confidence, but maybe not as high.
I had some fun spelunking the data. @RichardBuggs suggested…
I took him up on the challenge and computed it across the whole genome.
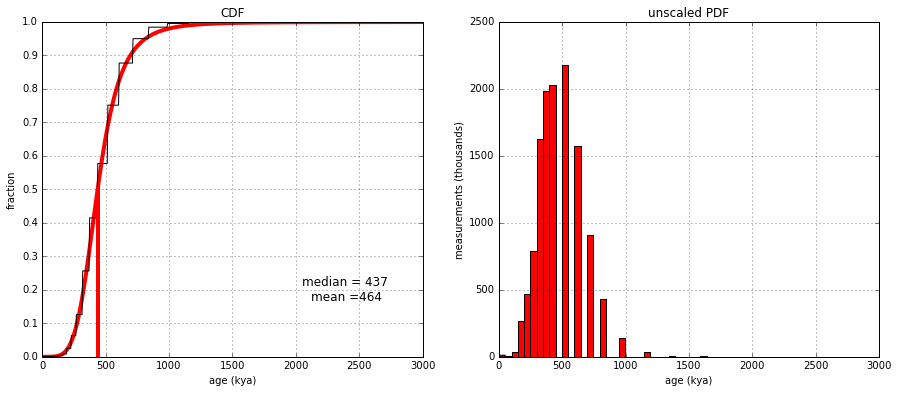
That puts a fair estimate of the TMR4A at 430 kya. I’d estimate that there is about 20% error one way or another, at least. That, could, perhaps be even extended down to 340 kya, when some think first Homo sapiens arise (though I would not bank on it). It would certainly work for the common ancestors of Neanderthals, Denisovans and Homo sapiens.
The exact path here is fairly technical, and I wanted to document it so that others could replicate these results. There is a lot in that thread, so this might be a helpful guide:
Genome-Wide TMR4A. A better estimate of TMR4A, based on the ArgWeaver data.
The last two may be most interesting if you have time to take a look. So have fun, I’ll look forward to seeing the conversation continue. I’ve been learning a lot.
Not All the Evidence
To be clear, we have still yet to deal with the stronger evidence, such as Ayalas work where the bottleneck hypothesis was tested, and he put a minimum bound on bottlenecks.
In your part (1) above, focusing on taxonomically classified homo sapiens narrowly rather than our hominid ancestors to modern day homo sapiens (obviously so very close genetically to interbreed), you would not even require an “Adam & Eve,” but merely an Adam or Eve in proximity to our other genetically compatible ancestors. A bottleneck of one if you will, a bit of a silly proposition that exposes the arbitrariness of such an endeavor.
In your part (2), should I take this as an affirmation of agreement with Steve’s claim below…extending this even further to 300KYA, which I believe echos Dennis’ framing of this issue as well?
To be more precise, they’re estimating the effective population size in time windows. The effective population size may or may not correspond well to the actual population size.[quote=“Swamidass, post:388, topic:37039”]
The point that @RichardBuggs is making is that population studies past about 500 kya are not powered to detect brief bottlenecks.
[/quote]
I would say rather that their power to detect brief bottlenecks has not been well explored. [quote=“Swamidass, post:388, topic:37039”]
Also, we were brought here by the claim that “Homo sapiens” never dip below a few thousand.
[/quote]
You may have been, but I certainly wasn’t brought here by that question. I think that question (even as you hashed it out with Dennis) is subject to multiple interpretations that lead to very different answers, and different people seem to be assuming different things about what question is actually being asked or answered. Here are at least some of the possible questions we might be addressing:
Could our ancestors have passed through a bottleneck of size two within some time frame? This is one possible interpretation of asking whether Homo sapiens could have passed through such a bottleneck, since “we” are Homo sapiens and Homo sapiens is us. It is a question that may be of scientific, theological and broad human interest.
If the time frame is the last 500,000 years, it is a question whose answer is unambiguously “no”, thanks to the ancestry many of us have in Neanderthals and Denisovans.
Can we answer question (1) based only on genetic variation data from the current human population (i.e. ignoring Neanderthals). This is effectively the question that is addressed by looking at haplotypes and coalescent methods (e.g. PSMC).
Did the African branch of our ancestry go through the same kind of tight bottleneck? In practice, this is the same question as (2), but with datasets restricted to individuals of African ancestry. It is the question I was actually addressing in my simulations (mostly because I wasn’t even thinking about Neanderthals). Both (2) and (3) are of technical interest to population geneticists, and might be of broader interest as well.
Did organisms that we would classify as Homo sapiens ever go through a tight bottleneck? This addresses not just modern H. sapiens, many of whom have Neanderthal ancestry, but also H. sapiens population prior to ~75,000 years ago, who (probably) didn’t. As I have previously pointed out, this is a very different question from (1). I view it as essentially unanswerable and nearly meaningless. Classification as H. sapiens as you look back in time is largely arbitrary and subjective. More importantly, there could well have been interbreeding within Africa between groups that we would classify as H. sapiens and group that we would not, but we have no way of ascertaining whether or when such events happened. Looking at modern genetic variation, therefore, cannot answer this question.
I agree with you that the terms are ambiguous. However, they were clarified. Dennis clarified that he mean Homo sapiens specifically and NOT Neanderthals, and pegged his claim on the time at which Homo sapiens arise. I’m sure he was mistaken, bit that is what he claimed.
I thought Neanderthals and Denisovans and Homo sapiens could share common ancestry at 500 kya, or even earlier. Did I miss something there?
That is how I understand the question as normally posed. Restricting it to Homo sapiens specifically seemed novel.
Exactly my point. Which is why I was genuinely surprised to see @DennisVenema make the claim. I did not realize that this is what he mean when he was making his heliocentric certainty claim.
Though, I’m not sure this is meaningless. Some may find this meaningful.
Then we may as well drop the “bottleneck” language pretending to have found some way to preserve genetic diversity in a founding original pair. We could just as easily say at some point that a lone homo sapien survivor, not even a mating couple, bred with a population of genetically compatible ancestors of ours. Those ancestors themselves could of course posses a mosaic of various proportions of Neanderthal, Denisovan, Homo Sapien, etc. DNA. Just as we do today. So in what scenario does this even remotely mean anything theologically?
You are ignoring an important point. What he was clarifying was the statement “we evolved as a population,” and he was indicating that by “we” he meant humans, Homo sapiens. He engaged in this clarification strictly to limit the time scales he was referring to, as can be seen in most of the quotes above.
What you are arguing is that since he clarified he meant Homo sapiens, the statement no longer has the meaning “we:”
I think when a statement is clarified, you keep “we” and add “humans” and “Homo sapiens;” I don’t see the justification for leaning all of our weight on “Homo sapiens” and jettisoning the other two to make your point.
I don’t think you are deliberately misinterpreting here. The conversation was long, involved and complex. Statements were made without the original text being quoted for reference. The conversation has continued quite some time additionally without anyone pinpointing the error, which always makes it difficult. However, at the end of the day, I do not think you have enough basis to say @DennisVenema made a mistake.
Exactly as i understood too, which is why it is an error. Restricted to the time scale in question (300 or 200 kya to present) we do not know if Homo sapiens dip to a single couple. That is why the claim seems to be in error. I that is not what Dennis meant, then his statements specifically excluding neanderthal’s don’t make any sense.
Of course if Dennis meant something else, he should speak up. I’m happy to be corrected by him, as i myself have been corrected by him in the past. Though that would make the string of statements he made about his definition of “human” incoherent. Eg how do we explicitly exclude Neanderthals and then mean Homo sapiens exclusively when discussing a “human” bottleneck? Especially when pop genetics only talks about ancestral bottlenecks, not homo sapien bottlenecks?
My honest opinion is that he, in good faith, misstated the science. That is common. I do the same and quickly correct myself; i’ve even done so more than once on this thread. Identifying and correcting errors is a good thing, right?
[quote=“Lynn_Munter, post:394, topic:37039”]
I don’t think you are deliberately misinterpreting here.
[/quote]Thanks also for clarifying that. This is just a well intentioned and good faith pushback. I’m sure @DennisVenema will clarify shortly.
The bible does not really teach that Adam is the sole progenitor of the human race. Gen. 2:1 says that “hosts” were created in heaven and on earth, and the word for host means an army. The instructions to mankind in chapter one sound martial, and nothing like the interactions with Adam and Eve in chapter 2.
The Christ-centered model of early Genesis explains Adam’s naming of Eve very elegantly. It was a funny thing for him to do because she had actually just gotten them both “killed”. But just prior to him calling her the “Mother of All the Living” we understand that the LORD God gave them a talk about “the seed” that would crush the serpent’s head. IOW, they were told that Christ would be born of a woman, and in Christ men can beat the curse and live eternally. So this passage makes perfect sense- if Genesis is viewed through the lens of Christ.
Somehow I think the author is twisting things a little too tightly …
"Having said that, I think Swamidass’s new work further illustrates the difficulty of answering far-out questions using mainstream methods. The tool used, ARGweaver, is fantastic in that it combines an enormous amount of real genetic information to model the past genetic history of humans. For this reason it gives the impression of being truly objective, and so when I first read it, I thought he had proved that there could be no bottleneck earlier than 300,000 years."
"However, a little digging into how ARGweaver works reveals that it too assumes a constant population, and uses this assumption to assign probabilities to ancestry trees. Therefore, again, it is not clear if it is really appropriate for asking questions about Adam and Eve. The particular reason why it is a problem is a bit technical: coalescence (branching but backwards in time) happens much more slowly in a large population. In a large population, the last few coalescents could take thousands of generations. But what if you have a small number of generations, drawing to a smaller and smaller population and terminating in a single couple? All the lineages will coalesce (down to at most four as explained above) but at a faster rate."
Its a bit more complex in this case. I think they misunderstood how argweaver works. I’ll explain later. I can’t say if they will publicly acknowledge it, but I can show what the misunderstanding was.
That is what this data shows. It is not consistent with a bottleneck before 300 kya.
This is not exactly correct. Rather, there is a weak prior placed on the coalescence times, that pulls the TMRCA and TMR4A estimates more recent (not more ancient) than would best fit the data. Once again, I’ll explain later in detail.
Aren’t you talking about a bottleneck of two? There are numerous studies that show bottlenecks in the human population associated with the “Out of Africa” event. I think it’s confusing to keep saying “no bottleneck” when what you really mean is “no bottleneck to two individuals,” unless you are arguing that you have disproved all previous papers on the subject.
Hi all, I hope you had a good Christmas and New Year. Sorry it has taken me a while to come back online since the break: I was away at a population genetics conference, and then have come back to a lot of urgent tasks, and a stack of marking. I have just taken the time to read through the posts that have been made since I last posted in this discussion, and I am delighted with the progress that has been made, and impressed with the time and effort that Joshua and Dennis in particular have been putting into this while I have been away.
As I come back into the discussion, I would like to reiterate (in response to some posts above) that I am assuming that we share common ancestry with apes and that chimpanzees are our closest living relatives from whom we diverged at least 6 million years ago. I am also assuming that no miracles have occurred in our past. I am also assuming that the earth revolves around the sun (sorry for wrongly saying “rotates” at one point, @glipsnort). I thought that I had been clear on these assumptions, and that it was obvious that much of what I am saying would not make sense if it were otherwise.
I would also reiterate that I do not come into this discussion with any assumption about whether or not there has been a bottleneck of two in the human lineage since the split from chimpanzees. I just come in asking the question of whether or not this hypothesis has been tested. I am not taking a position about the possible timing of such a bottleneck if there were one. If anyone is frustrated that I am not taking a position on these matters, I apologise, but I simply have not explored this issue and the relevant evidence enough to feel able to take a position. This is why I am engaging in this discussion. I am here to learn and to weigh the evidence. I hope that at some point in the future I will know enough to be able to take a position, or to be able to conclude that we simply can’t know for sure from the current evidence.
I see that some references have been made to other blogs that claim that I am taking a stronger position on these issues. Such blogs are mistaken. I tried to correct the author of one such blog a few weeks ago, and asked for it to be changed, but my request was not granted.
I am very glad that @DennisVenema now agrees with me that Zhao et al (2000) does not support the case he makes in Adam and the Genome and I would assure Dennis that I do not view this as “win” for me. I have never seen this discussion in terms of a competition. Indeed, the fact that Dennis is willing to make this admission in the light of evidence and explanation has won him respect as a scientist, in my eyes. I am glad that we examined this paper, and Dennis’ earlier claims about it, in such detail, as it helped us all to think more clearly about the nature of evidence that could be used to test a bottleneck hypothesis. In particular, it has led on to the very interesting work by @swamidass in TMR4As.
I have learned a lot by reading the posts by @swamidass on TMR4As, and the comments about his analyses by @DennisVenema@glipsnort and others. Joshua has brought a great deal of expertise and time to this discussion and I am very grateful for that. This is highly interesting and informative. I think this is getting close to a test of the bottleneck hypothesis. I am still taking in some of the details of what Joshua has done and may have more comments in due course. I do think that the coalescent models used in a test of the bottleneck hypothesis would need to include the effective population size decreasing down to two as we go back in time. I realise that this would be a lot of work, but I do think that this would be necessary. Do correct me if I am missing something, Joshua. I am grateful for the many excellent points that you have made over the past few weeks.
“Swamidass stresses that he does not actually believe all humanity derived from a single couple but he has shown that it is possible, if the couple lived more than 300,000 years ago.”
@Swamidass In your mind, is there a difference between saying “science has shown it is possible” and “science cannot rule out the possibility”? Don’t you usually say the latter not the former?
So, drawing from your above statements, you seem to be asking us to believe that in your experience as a geneticist you’re completely unconvinced one way or the other on common ancestry. Or that humans didn’t exclusively descend from an ancestral pair say 6,000-10,000 years ago. You just have no idea. It’s a toss up. If only you may have sufficiently explored those topics in your relevant field of expertise, maybe you might have reached a conclusion one way or the other. But alas it’s not to be.
Based on your statements this is what you would have us believe. Which I have to tell you does put a strain on our credulity. One I personally may be unable to bear. But putting that aside, it’s very difficult to imagine what sort of case you would find convincing enough to have satisfactorily tested the “hypothesis” that humans did not descend from an exclusive ancestral pair in the last hundreds of thousands of years if you still have yet to be convinced that the “hypotheses” of common ancestry or, presumably, whole human populations persisting past 10K years ago have been adequately tested. In fact, we have no idea what you think has been adequately tested. So there’s a credibility issue here Richard. If you want us to have confidence you would recognize and acknowledge adequate evidence to affirm such a hypothesis as we’ve been discussing here, you’re giving us every reason to doubt your ability or will in this regard.
Here, we are discussing a bottleneck of 2 for a single generation, followed by rapid expansion. In this case, we are not considering miracles, and we entirely expect this couple to be a heterozygous, and not clones of one another. We are most curious about a “bottleneck” earlier than 300 kya and as far back as 2 mya.
Good point too @Christy. I do not think we are going to find positive evidence for a bottleneck. However, there might be enough ambiguity in the evidence we cannot rule it out in the deep enough past. This is really a question about what the evidence does and does not tell us, and the strength with which it speaks.
I would also add that there is a categorical difference between this question and the regular arguments from Intelligent Design. Here, there is no indirect invocation of divine action (we’ve ruled out special creation), and @aguager (and others) engaging evidence in a manner largely consistent with what we see with mainstream scientists. At times the rhetoric goes places I think ultimately undercuts their case (e.g. when that article connects this effort to ID), but the actual inquiry is recognizably scientific. We are using the rules of mainstream science, asking a valid question of the data.
It is for this reason that I feel this question needs to be taken seriously.
You have been clear on this.
This is very unfortunate @RichardBuggs. I’m very sorry to hear this. I request that you clarify either publicly or in a private message to me how you have been misrepresented. I do not want to accidently ascribe a view to you that is not yours.
I should also emphasize that when I address the ID movement, that does not necessarily include you. Though they have take some delight in your public effort, I’m not sure I’ve seen any public evidence that you are associated with them. My references to ID are not meant to connect you to them, unless you so wish to be connected to them.
In truth, I’ve learned a lot too. This has been an interesting and informative direction.
ArgWeaver Does Not Assume Large Population
It appears you are drawing upon an observation by Andrew Jones at the DI, who writes:
However, a little digging into how ARGweaver works reveals that it too assumes a constant population, and uses this assumption to assign probabilities to ancestry trees. Therefore, again, it is not clear if it is really appropriate for asking questions about Adam and Eve. The particular reason why it is a problem is a bit technical: coalescence (branching but backwards in time) happens much more slowly in a large population. In a large population, the last few coalescents could take thousands of generations. But what if you have a small number of generations, drawing to a smaller and smaller population and terminating in a single couple? All the lineages will coalesce (down to at most four as explained above) but at a faster rate. On Prejudiced Models and Human Origins | Science and Culture Today
This turns out, in my opinion, not to be the correct assessment. I’m going to do a more detailed post on this in the future, but can explain a little bit more now.
ArgWeaver is using a prior on trees, that is parameterized by population size (N = 10,000). The language of “assumes a large population size” is just correct. It is more accurate to say that is starts with a weak prior belief of a population size of 10,000. It is a weak prior belief, because it is designed to be quickly overcome by data. Let me give you two reasons why it does not impact the results I’ve put out on TMR4A. These will be expanded later on some posts that I’ll link here when done:
As a prior, this is not an assumption, but a starting belief that is meant to be overridden by the data. The only way that the ArgWeaver program uses the population size is in computing this prior. Population size is neither simulated nor modeled in the program except for placing this weak prior on population size. Remember, priors are not assumptions or constraints.
The ArgWeaver output files tell us the strength of the prior vs. the data, and it is just about 5%. That means the model output is dominated 95% by the data, and not by the prior (as it is designed).
The prior distribution for TMR4A is at about 200 kya (which I will show later), but we measured the TMR4A at about 420 kya. That means the data is pulling the estimate upwards from the prior, not downwards.
This last point should end any confusion. To draw analogy, it’s like we measured the weight of widgets, with the weak starting belief that the average weight of these widgets is 200 lb. After weighing several of them, and taking the prior into account, we compute the average weight is 420 lb. The fact we used a prior could be an argument that the real average is greater than 420 lb, but that is not a plausible argument that the true average is less than 420 lb. The prior, in our case is biasing the results downwards, not upwards.
With that in mind Dr. Jones was just mistaken when he writes:
The tool used, ARGweaver, is fantastic in that it combines an enormous amount of real genetic information to model the past genetic history of humans. For this reason it gives the impression of being truly objective, and so when I first read it, I thought he had proved that there could be no bottleneck earlier than 300,000 years…However, a little digging into how ARGweaver works reveals that it too assumes a constant population, and uses this assumption to assign probabilities to ancestry trees.
I would submit that, given what I have just explained, that this is not a reason to doubt the results that I put forward. I do believe this data shows there could be no bottleneck earlier than 300,000 years without either miracles or our ancestors have vastly different mutation rates than us. Both those possibilities, howver, are off the table right now.
There are three ways that could prove me wrong here:
Do an experiment with simulated data, showing that the prior is strong enough to override detecting a bottleneck before 300 kya in the argweaver code. (not likely)
Modify argweaver to no longer use the prior (which is fairly easy), and run it on the same dataset, demonstrating that the estimated TMR4A goes down, not up. (not likely)
Find another way that population size is used by argweaver that I missed, and show it has a stronger effect that I imagine. (not likely)
Of all these #3 is most likely way to show me wrong here. Until that happens though, I think that 420 kya +/- 100 kya is a reasonable bound on when we think a couple bottleneck could have occured. Do you agree @RichardBuggs? I’m being fairly generous in how I set the confidence interval there too.
My Next Steps
My next steps, when I get around to it, are:
To test the ability of PSMC, MCMS and/or ArgWeaver to detect bottlenecks on simulated data. Have the simulation code working, and it’s really a matter of running the code. My instinct tells me this will increase the bound to about 500 kya, but I won’t know till I run it.
Recompute TMR4A while weighting coalescents by the segment length. Failure to do this before, I think, is the biggest source of error in the prior analysis. I think it might shift things around a small amount…
Using the argweaver data to estimate population size. If this works correctly, ti should increase our confidence that this is a good proxy for understanding the success and failure of PSMC and MCMS. Incidentally, MCMS uses a very similar model as ArgWeaver (but a different representation).
@DennisVenema and @glipsnort correct me if I’m wrong, but it seems that the LD data is really not worth getting into in detail, as PSMC, MCMS and Argweaver are (essentially) modeling the LD data with much higher accuracy than other approaches. The key thing is understand how these methods model the DNA, which by extension is the best way to understand all the LD data. Do you agree?
Do You Agree?
For the reasons outlined above, I’m not sure this is a valid critique. Though I do agree, this has been highly informative for all of us, including me. I had no idea what the data would show till I did this analysis.
In Argweaver, the size of tree is determined primarily by (1) mutation rate (2) allelic diversity, and (3) only to a small amount by the prior. There is no sensible way to “include the effect of population size decreasing.” I would endorse running the model again without a prior, but as I’ve shown there is no good reason to think that will reduce the TMR4A time. I think that should settle this concern. Right?
@RichardBuggs, you pushed @DennisVenema to concede your point on Zhoa 2002. That ended up being valuable, as it clarified some key strengths and weaknesses of the evidence. Respectfully, would you reciprocate? Do you acknowledge the ArgWeaver evidence seems to rule out a single couple bottleneck before 300 kya? Can you agree to that? If that is not something you agree with, please clarify why not. Of course, if you see a solid technical problem that I missed, that is all the more reason to clarify. Let’s get to the bottom of it.
Josh, I do not believe Richard would agree to this. I also do not believe he would agree to this evidence ruling out a bottleneck to 2 within the past 10K years in fact. Go ahead and ask him as a follow up. But I think he’s been pretty clear that nothing he’s seen so far has lead him to the view of any kind of minimum bound on when a bottleneck may have happened. Or if there is something that has lead him to such a view, he’s declining to say so. And of course his position on this lower bound within the YEC timeframe has been asked of him repeatedly, and so it would follow this timeframe is included in his statement below:
This is very counterintuitive, but exactly how things work out in a scientific community. We end up respecting those who concede mistakes. We trust those that retract mistakes. So admitting mistakes certainly does win people respect among scientists.